
Veštačka inteligencija
Pitali smo ChatGPT – koliko ljudi u Srbiji koristi ChatGPT
Svega pet do deset odsto ljudi u Srbiji koristi ChatGPT, pokazuju podaci koje dostavlja veštačka inteligencija

Čudnovati zakoni kao Zipfov javljaju se u prirodi i našem okruženju kao snažni nagoveštaji moćnijih i fundamentalnijih sila
Ova rubrika se sastoji od 457 različitih reči. Kao i u svakom drugom novinskom tekstu, ali i bilo kom pisanom komadu, romanu ili poemi, zakonskom aktu, dugom ili kratkom mejlu ili običnoj poruci koju ostavljate na frižideru, neke od upotrebljenih reči pojavljuju se u njemu samo jednom, neke dva ili tri, a neke mnogo puta. No, ako pažljivo prebrojimo leksičko stanje, saznajemo da je najčešća reč u ovom tekstu veznik „i“ koji se javlja 30 puta. Na drugom mestu je „u“ sa 25 pojavljivanja, zatim glagol „je“ sa 21, na osmom reč „tekst“ sa 9, a reč „no“ sa 4 pojavljivanja… Primećujete kako učestalost postaje sve manja i manja? Ako bismo ove frekvencije brojali kroz ceo tekst, videli bismo da one brzo opadaju ka najvećem broju reči – onih koje su upotrebljene samo jednom.
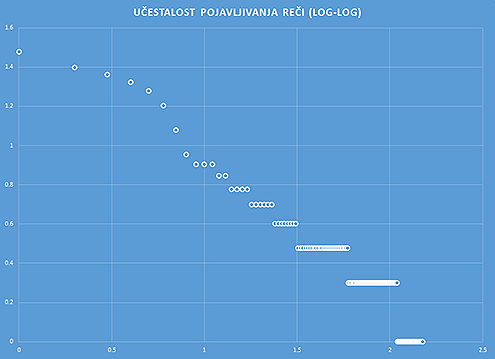
Situacija je donekle nalik na košarkašku utakmicu gde najbolji šuter (ovde je to reč „i“) ima mnogo postignutih poena, drugi iza njega dvostruko manje, treći dvostruko manje od drugog i tako redom. Većina igrača zapravo ima samo jedan poen. Trener takvog tima nema izbora nego da radi sa nekolicinom bez nade da će svi postati zvezde. Sa druge strane, fizičari, hemičari i inženjeri će svaki takav brzi pad učestalosti po automatizmu opisati nekom od takozvanih stepenih funkcija. Ako se nalik na njih poigrate matematikom prebrojavanja reči u ovom tekstu, pa njihove frekvencije nacrtate na logaritamskoj skali, dobićete nešto zanimljivo – pravu liniju. Takva matematička pravilnost (videti sliku) govori da je ovaj tekst sklopljen tako da frekvencije pojavljivanja reči u njemu nisu slučajne – reči nisu tu zbog svog značenja, nego slede neku složenu matematičku konstrukciju.
Možda ste se zapitali kako su ove ovde reči odabrane a da budu tako prebrojane. I kako je uopšte napisan jedan ovakav, naizgled sasvim običan tekst u novinama (i to takav da ne sadrži ništa spoljno, ništa o odvratnim političkim prilikama u zemlji i svetu, niti malo šire, o našoj mučnoj svakodnevici ili ukletosti čoveka našeg doba), nego se potpuno suprotno ideji novinskog teksta bavi isključivo sam sobom, kao kakav nedorasli tekst adolescent koji se samopreispituje i iznutra prebrojava. Kako se pravi razumljiv tekst koji sledi tako složeno unutrašnje pravilo? I šta nije u redu sa autorom koji se upušta u takav besmisleni matematičko-leksički poduhvat?
Zapravo, nema ništa posebno u ovom tekstu. Ovakva pravilnost važi i za bilo koji drugi, ma koliko dug i ma kako napisan, na bilo kom jeziku kojim ljudi govore. Reč je o takozvanom Zipfovom zakonu, koji tvrdi da će učestalost reči u nekom tekstu uvek slediti stepenu distribuciju. Zakon je dobro znan i u lingvistici i u matematici, a ovde je primenjen naknadno – nakon što je napisan, tekst je analiziran u jednom od brojnih tekst analizatora kakvih ima prilično na internetu (goo.gl/DNrl1V), a dobijena statistika je i predstavljena grafikom. Autor je, naravno, vodio računa i koliko se takva statistika menja pri potonjem unosu ovih podataka u sam tekst.
Zipfov zakon je inače dobio naziv po američkom lingvisti Džordžu Kingliju Zipfu (1902–1950), koji je pokušao da objasni zašto jezik sledi takvu pravilnost. Mada je o Zipfovom pravilu napisano mnogo radova i nekoliko uzbudljivih knjiga, ovaj zakon spada u one empirijske pravilnosti za koje u nauci ne postoji teorijsko, suštinsko objašnjenje. Takvi zakoni se javljaju u prirodi i našem okruženju kao snažni nagoveštaji moćnijih i fundamentalnih zakona. No, ako i ne razumemo šta to iza teksta ulaže toliki trud da složi reči po istom pravilu, Zipfov zakon možemo da primenimo na bilo koju knjigu, na primer Tolstojev Rat i mir, i pokazaće se da jednako važi u šest različitih prevoda.
Na Zipfov zakon mi je pažnju skrenuo prijatelj – od onih tipova koji su spremni da eksperimentišu ne samo na svom okruženju ili svom tekstu nego i na sebi, samo da vide šta je unutra – koji ga je primenio kako na romanu Na Drini ćuprija tako i na raznim drugim tekstovima na srpskom jeziku. Moderni istraživači su se takođe igrali, okušavali sa raznovrsnim mogućim primenama zakona, a posebno su pomoću njega proučavane reči sa dna raspodele, one koje se u tekstu javljaju samo jednom. One se u lignvistici nazivaju hapax legomenon, što bukvalno znači jednom izgovoreno. Jedan broj istraživača, posebno šekspirologa i biblista, video je ne baš ostvarenu nadu da matematika hapaksa možda skriva sam kod poetike, autorski pečat, što bi, na primer, bio jedan koristan instrument u borbi protiv plagijata. No, izgleda da Zipf krije i nešto drugo, neku tajnu samog jezika, izvan autorovog domašaja. Jedno od mnogih potencijalnih objašnjenja ovakve pravilnosti jeste da ljudi pri komunikaciji slede takozvani Princip najmanjeg truda. I da je u prirodi onog što pišemo i čitamo upotrebljen najmanji mogući broj reči da se razumemo. Naravno, sa toliko truda ne mogu sve reči postati zvezde.
Svega pet do deset odsto ljudi u Srbiji koristi ChatGPT, pokazuju podaci koje dostavlja veštačka inteligencija

Našoj zemlji je ovih dana verovatno dosta plamena koji bukti, ali jedan praznik kao i svake godine tradicionalno se obeležava upravo paljenjem vatre. Deca po selima i gradovima za Petrovdan pale lile – najčešće koru trešnje ili breze na dugačkom prutu – i mašući njima trčkaraju sa drugarima

Najbolji srpski teniser Novak Đoković poražen je u polufinalu Vimbldona od Janika Sinera. Italijanski teniser će se u nedelju protiv Karlosa Alkaraza boriti za titulu na najprestižnijem svetskom grend slemu

Na Adi Ciganliji je došlo do pomora ribe. Smatra se da je glavni uzrok nizak vodostaj. Ipak, detaljne analize i izjave nadležnih tek se čekaju

Sa medija i pogotovo društvenih mreža čeka nas baražna paljba loših vesti. Kako ne potonuti u njih, a ipak znati šta se dešava oko nas

Protesti u Srbiji ne nameću više pitanja „da li“ i „ako”, oni su postali sistemski događaji. Trpeljivost u društvu preokrenula se u nezajažljivu potrebu za normalnošću, za pravnom državom

Aleksandar Vučić više nije u stanju da povrati ravnotežu u pobunjenom društvu. To se najbolje vidi u ravni govora: nijedno njegovo baljezganje više ne prolazi

Ako smo neutralni dok studente zatvaraju, devojke i momke mlate na pravdi boga, zatiru demokratiju, neistomišljenike dehumanizuju, nastavljaju korupciju koja ubija i još mnogo toga poganog rade – onda ništa

Arhiva nedeljnika Vreme obuhvata sva naša digitalna izdanja, još od samog početka našeg rada. Svi brojevi se mogu preuzeti u PDF format, kupovinom digitalnog izdanja, ili možete pročitati sve dostupne tekstove iz odabranog izdanja.
Vidi sve












