Očekuje se da će povećanje produktivnosti usled sve šire primene veštačke inteligencije uvećati globalnu ekonomiju tokom ove decenije za više od 15.000 milijardi dolara. Ljudi će, makar u proseku, postati bogatiji, ostaje samo da vidimo kako će to bogatstvo biti raspoređeno. Ako najveći deo tog novca ode u džepove malobrojnih tehnoloških mogula umesto u nova, kreativna i bolje plaćena radna mesta, može se zaista ispostaviti da je razvoj AI-a za veći deo čovečanstva bio korak unazad
Tetris je bio enormno popularan u svoje vreme. A onda Jutjub, Fejsbuk i Tik-Tok. Ako se, međutim, meri vreme koje je potrebno nekoj aplikaciji da stekne prvih sto miliona korisnika, sve ih je zasenio “ChatGPT” – program koji je sposoban da razume “običan jezik” i, korišćenjem veštačke inteligencije, daje odgovore na potpuno proizvoljna pitanja.
Za reč “chat” znamo da predstavlja “razgovor, ćaskanje”. Ali, šta tačno znači ono “GPT” u imenu programa? U pitanju je skraćenica za rogobatnu englesku frazu “Generative Pre-Trained Transformer” koja u najkraćem opisuje suštinu ChatGPT-a. Ovaj program je, pre svega, “generativan”, sposoban da proizvede novi tekst na bazi već postojećeg. Bot je, takođe, “unapred istreniran” tako što su mu prezentovani silni terabajti teksta sa interneta uključujući kompletnu Vikipediju, bez namere da bot postane ekspert u bilo kojoj posebnoj oblasti ljudskog znanja. Na kraju, ChatGPT je “transformer”: ova reč detaljnije opisuje arhitekturu neuronske mreže koja se krije ispod haube (vidi antrfile “Kratka istorija ChatGPT-a i mašinskog učenja”). Transformeri su se kao koncept prvi put pojavili 2017. godine kao deo novog rešenja za mašinsko prevođenje teksta.
ilustracija: dall-e2…
BESKRAJNO VEŠT, SKUPOCENI “POGAĐAČ” REČI
Sve ovo smrtnicima kao što smo mi ne znači mnogo. Kako ChatGPT zapravo radi? Ako aplikaciju predstavite kao mašinu koja s jedne strane prima pitanja a na drugoj izbacuje odgovore, videćete da je ono “između” zapravo jedan veliki jezički model, crna kutija koja ima fantastičnih 175 milijardi podesivih parametara. Ove parametre, zbog njihovog broja, nije moguće konfigurisati “ručno”. Umesto toga, ChatGPT ih sam podešava tokom perioda “učenja”, dok se “hrani” milionima stranica gotovog teksta. Dok “čita” servirani tekst, ChatGPT neprekidno pokušava da pogodi narednu reč što mu, u početku, nikako ne polazi za rukom. Međutim, kad god napravi grešku u proceni, ChatGPT sam sebi dodeli “packu”, stimulans kojim sam koriguje svoje parametre kako bi naredni put izabrao bolju reč. Na ovaj način ChatGPT polako stiče predstavu o jeziku, odnosu među rečima, njihovom značenju i kontekstu upotrebe. Tokom višemesečnog treninga, principi govornog jezika bivaju pretočeni u brojeve koji kontrolišu ponašanje mašine. Posle ove, “nenadgledane” faze učenja, na red dolazi fino doterivanje aplikacije korišćenjem velikog broja pitanja i ekspertskih odgovora iz više uže definisanih oblasti.
Nakon ovog “drila”, svi konfigurabilni parametri bivaju trajno zamrznuti i ChatGPT je konačno spreman da odgovara na vaša pitanja. Svako pitanje prolazi kroz komplikovanu semantičku analizu gde bot, korišćenjem mehanizma za “fokusiranje pažnje”, utvrđuje kojim rečima u pitanju treba da prida veću ili manju težinu. Ali kako nastaje odgovor? Verovali ili ne, isključivo “pogađanjem”! Bot nema pristup internetu i ne može da na njemu pronađe traženu informaciju kao što to čini Gugl. Umesto toga, bot počinje da “sriče” odgovor, reč po reč, neprekidno pokušavajući da za narednu reč izabere onu koja, na bazi ogromnog “iskustva” stečenog učenjem, izgleda “najlogičnije” u datom kontekstu, uz malu dozu slučajnosti, kako bi odgovori bili raznovrsniji. Uzmite, na primer, započetu rečenicu: “Danas me je posetio ____”. Mnogo je verovatnije da na mestu nepoznate reči stoji “brat” nego “zmaj”. ChatGPT zaista nije mnogo više od toga: beskrajno vešt, skupoceni “pogađač” reči što svoju fleksibilnost crpi iz ogromnog broja parametara koji u sebi čuvaju duh i pravila govornog jezika.
DALL·E 2023-04-08 19.49.55 – a large neural network, steampunk styleUMETNIČKO DELO: Dall-E2
“OPŠTA INTELIGENCIJA”
Koliko je ChatGPT dobar? Probajte i sami na adresi https://chat.openai.com, ili se malo poigrajte “Bingom”, Majkrosoftovom verzijom Gugla u koju je odnedavno ugrađen i ChatGPT. Utisci će prvenstveno zavisiti od dubine do koje ste spremni da idete kada je u pitanju istraživanje mogućnosti ovog “govornog automata”. Ako su pitanja jasna i jednostavna i ako se odgovor može dobiti rezimiranjem sadržaja koji već postoji na internetu, ChatGPT deluje zastrašujuće moćno: odgovori su ispolirani do perfekcije, precizno kondenzovani i nedvosmisleni. Ako mislite da ChatGPT odnekud prepisuje, to je samo donekle tačno: odgovori koje će dve osobe dobiti na identično pitanje mogu da budu potpuno različiti po formi iako su suštinski identični. I ne pokušavajte da ChatGPT zbunite tablicom množenja ili dečjim pitanjima: “Šta je teže, kilogram vune ili kilogram olova”? ChatGPT nije vašarska igračka koja se može rasturiti jeftinim trikovima.
Budimo realni: ChatGPT generiše nestvarno dobre tekstove. Tokom jednog eksperimenta, ekipa stručnjaka uspela je da u svega 52 odsto slučaja utvrdi da je tekst kreirao bot a ne čovek, što je jedva malo bolje od pogađanja bacanjem novčića. Kao prevodilac, ChatGPT je pretekao sve svoje rivale, uključujući do skoro neprikosnoveni Google Translate. ChatGPT ne samo da odgovara na pitanja, u stanju je da piše vesti, impersonifikuje istorijske ličnosti, da odgovore daje u stihu ili u stilu antičkih filozofa. Zahvaljujući ChatGPT-u, možete da “intervjuišete” Marka Aurelija, Džona Lenona, Isusa Hrista ili Džona Vejna, da uporedite stilove vladanja najvećih američkih predsednika ili vodite beskrajne diskusije o potpuno apstraktnim stvarima. ChatGPT ume da napiše novu epizodu Zvezdanih staza, da napravi recept za ručak na bazi sastojaka u frižideru, da predloži rođendanski poklon, da priča viceve, da sastavi otkazno pismo ili dotera biografiju…
2 – ChatGPT kad pogadja…
Đaci ga već uveliko koriste za pisanje školskih sastava, a kako i ne bi kad ChatGPT ume da prepriča skoro svaku knjigu koju bi đaci, inače, morali da pročitaju. Briljantan je i kada su kompjuterski, programski jezici u pitanju: u stanju je da generiše savršeno ispravan softverski kod na bazi verbalnog opisa, možda zahvaljujući činjenici da mašinski jezici operišu relativno malim fondom reči i imaju jasno definisanu sintaksu. ChatGPT takođe ume da piše pesme, note i akorde za gitaru, da prepričava Harija Potera koristeći Eminemov reperski rečnik ili oponaša imaginarne junake iz stripova ili crtanih filmova. I na kraju, ChatGPT ume da objasni zašto je broj 42 odgovor na pitanje svih pitanja. Kada sve ovo saberete, ne čudi što ima dosta onih koji tvrde da je ChatGPT prvi kompjuterski program koji demonstrira istinsku “opštu inteligenciju”. Po njihovom mišljenju, bot poseduje određenu količinu zdravog razuma, solidan nivo razumevanja i sposobnost razmišljanja.
1 – ChatGPT kad gresi…
LOGIKA KAO SLABIJA STRANA
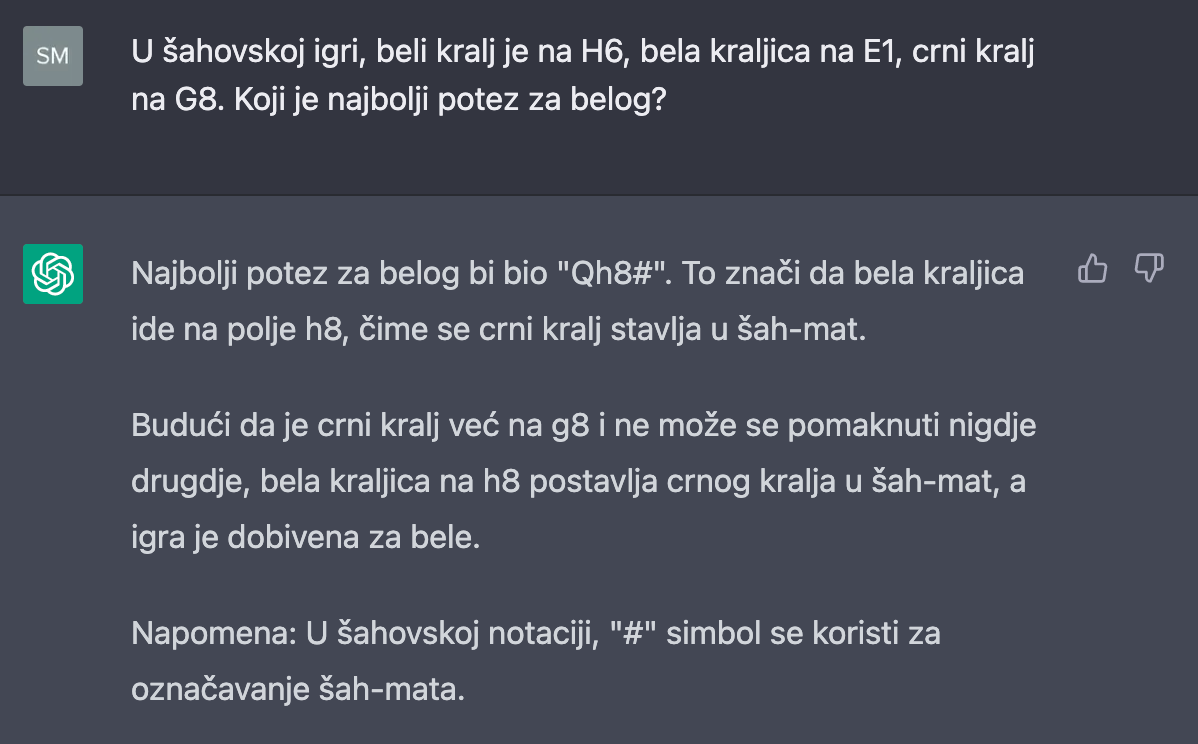
Ipak, kada zagrebete malo dublje, postaće vam jasno da ChatGPT zapravo “pojma nema” o čemu piše i da mu logika nije jača strana. Kada mu postavite pitanje, on ne pokušava da u moru pročitanih tekstova nađe odgovor. Umesto toga, on se trudi da pronađe formulaciju koja, po duhu i formi, “liči” na tačan odgovor. Recimo, bot je do sada pročitao mnogo šahovskih knjiga i video mnogo šahovskih partija, ali i dalje ne “kapira” elementarna šahovska pravila. Manjak inteligencije naročito se vidi kada ga zatrpate pitanjima koja zahtevaju kreativno razmišljanje, gde ne postoje primeri na koje bot može da se ugleda.
Autor ovog teksta nije dovoljno stručan da ChatGPT napadne sofisticiranim pitanjima iz domena filozofije, lingvistike ili istorije, ali ponešto zna o matematici i fizici. Ispostavilo se da je ChatGPT lako “slomiti” relativno jednostavnim zagonetkama, čak i onim koje su nebrojeno puta ponovljene na internetu. Na pitanje koliko bi bio debeo papir koji je 50 puta presavijen na pola, bot “pametno” zaključuje da se radi o stotinama miliona kilometara (što je tačno), ali onda dodaje još jedan paragraf u kome, potpuno pogrešno, tvrdi da je to više od prečnika čitavog vidljivog kosmosa (nije ni približno). Jednostavno, bot ne razume brojeve, naročito one “malo veće”. Da bi razumeo njihove odnose, ispostavlja se da savršeno poznavanje sinatkse i semantike govornog jezika nije dovoljno. Ako bot gađate još težim pitanjima, recimo, ako zatražite da dokaže da se broj “pi” (3,14) ne može napisati kao razlomak (krupan zalogaj čak i za profesionalne matematičare), ChatGPT će se upetljati kao “pile u kučine” pokušavajući da složi priču od napabirčenih fragmenata dokaza koji se odnose na slične, ali zapravo sasvim drugačije probleme.
DALL·E 2023-04-08 19.51.58 – planet eart as giant ball made of pipes, dials, buttons and levers, with moon orbiting in the same stylePLANETA ZEMLJA: Ilustracija Dall-E2
Internet je prepun primera u kojima ChatGPT “halucinira”, vidi stvari i događaje koji ne postoje i izvlači zaključke upitnog kvaliteta. Ispostavlja se da sistem “pogađanja” naredne reči ne može da bude zamena za kreativno razmišljanje, logiku i intuiciju. ChatGPT liči na čoveka koji je pročitao milion knjiga, ali nikad nije izašao u svet, da svoju načitanost obogati iskustvom i na bazi toga razvije sopstvenu inteligenciju. Ni dete ne može da shvati svet isključivo čitanjem knjiga, neophodna je interakcija sa svetom koji ga okružuje. To iskustvo omogućava nam da informacije povežemo sa značenjem i tako steknemo osećaj realnosti. Upravo činjenica da ChatGPT nema nikakav dodir sa svojim okruženjem, da nije deo sveta koji opisuje, predstavlja ključni argument onih koji tvrde da ChatGPT ni danas, ni u nekoj budućoj inkarnaciji, ne može da razvije sopstvenu inteligenciju.
Stvar komplikuje i činjenica da je veliki deo ljudskog znanja implicitnog karaktera: neke stvari jednostavno znamo, ali ne umemo da ih objasnimo rečima i prenesemo nekom drugom. Primer je, recimo, vožnja bicikla, plivanje ili stajanje na jednoj nozi. Za ove veštine ne postoji pisani recept, najvažnije je iskustvo. Mi, jednostavno, znamo mnogo više nego što možemo da ispričamo. Zato su male šanse da će ChatGPT gutanjem bizarno velikih količina teksta ikad naučiti da vozi bicikl ili stoji na jednoj nozi, čak i u svom virtuelnom svetu.
ChatGPT pritom svoju snagu bazira na tekstovima pokupljenim s interneta, koji su često upitnog kvaliteta. Nije zato čudo što je, korišćenjem sugestivnih pitanja, relativno lako naterati ChatGPT da bude pristrasan ili generiše odgovor koji je mizogin, rasistički, antisemitski ili, jednostavno, zatucan. Sve je to bot negde već video i memorisao u svojim brojevima ne znajući da li se radi o istini ili laži. Iako autori programa neprekidno rade na tome da unapred isfiltriraju toksične odgovore (i pitanja koja do njih dovode), uspeh je još uvek polovičan. Ovom botu pogotovo ne treba verovati kada su u pitanju životno osetljiva pitanja: lekarske dijagnoze, finansijske transakcije, krupne životne odluke i druga pitanja “života i smrti”.
Na kraju, postavlja se pitanje kako će ChatGPT izaći na kraj sa samim sobom. Danas se ovaj bot “hrani” tekstom s interneta. Ali šta će biti kada veliki procenat tog teksta bude mašinski generisan, upravo od strane tih istih botova? Mašina će početi da “uči” tako što će reciklirati sopstvene reči, poput pisca koji čita samo sopstvene knjige. Količina petparačkog digitalnog smeća radikalno će se povećati (kao da ga i ovako nemamo dovoljno), možda do tačke kada ni Gugl neće moći da pronađe bilo šta vredno u toj ogromnoj deponiji banalnosti. Ilon Mask, jedan od osnivača kompanije “Open AI”, traži da se proglasi moratorijum na dalji razvoj inteligentnijih botova jer, u ovom trenutku, niko ne zna u kom pravcu ide sadašnji vrtoglavi razvoj (količina upotrebljenog hardvera duplira se na svaka tri-četiri meseca). Italija je već privremeno zabranila ChatGPT (zbog neadekvatne zaštite privatnosti), a o sličnoj meri razmišljaju i neke druge zemlje.
I pored toga, očekuje se da će povećanje produktivnosti usled sve šire primene veštačke inteligencije uvećati globalnu ekonomiju tokom ove decenije za više od 15.000 milijardi dolara. Ljudi će, makar u proseku, postati bogatiji, ostaje samo da vidimo kako će to bogatstvo biti raspoređeno. Ako najveći deo tog novca ode u džepove malobrojnih tehnoloških mogula umesto u nova, kreativna i bolje plaćena radna mesta, može se zaista ispostaviti da je razvoj AI za veći deo čovečanstva bio korak unazad.
Promene koje se moraju prihvatiti
Postoji li opasnost da nas ChatGPT, zahvaljujući svojim neverovatnim sposobnostima, potisne na margine života? Prema nekim analizama, sve intenzivnija upotreba veštačke inteligencije (AI) dovešće do toga da oko 15-30 odsto radnih mesta postane suvišno do kraja 2030. godine. Više nam neće biti potrebni stručnjaci, sve će ih zameniti ChatGPT ili neki njegov klon.
U sve većem broju restorana roboti polako zamenjuju konobare. Industrijske montažne trake danas su potpuno automatizovane, u mnogim halama nema nijednog radnika. Kompjuteri ugrađeni u automobile kao što je “tesla” danas mogu u potpunosti da odmene vozača i svedu ga na nivo pasivnog putnika. U strahu za svoje radno mesto su i prevodioci, novinari, programeri, administrativni službenici, radnici u kontakt-centrima, nastavnici… Sve njih je, već danas, u većoj ili manjoj meri, moguće zamenti inteligentnim botovima kao što je ChatGPT. Čak ni medicinski radnici nisu sigurni: u vodećim svetskim zdravstvenim ustanovama sve više se koriste neuronske mreže za postavljanje dijagnoze na osnovu analize radioloških snimaka. Ispostavilo se da mašine uočavaju rane maligne procese efikasnije nego ljudi.
Istorija ljudskog rada je, zapravo, priča o tome kako su ljudi teške i dosadne poslove postepeno prenosili na mašine. Te mašine danas su stigle do tačke kada počinju da se bave logikom i zaključivanjem, da komuniciraju na govornom jeziku, da prepoznaju zvuk i oblike. Ovoga puta mašine preuzimaju i intelektualne, a ne samo fizičke poslove. Ako se sadašnji trend nastavi, reklo bi se da će, pre ili kasnije, sve biti automatizovano i da nijedno radno mesto više nije sigurno jer jednoga dana neće biti potrebno.
Da li su ljudi i mašine zaista međusobno suprotstavljeni? Ova dilema počiva na pretpostavci da su mašine i ljudi ravnopravni. Srećom, oni to nisu i još dugo neće biti. Mašine su možda brze, hladno racionalne i tačne, ali ne mogu da se pohvale intuicijom, kreativnim razmišljanjem ili emocionalnom inteligencijom. Ljudi su, uz to, sposobni da se adaptiraju na promenjene okolnosti i svoj rad prilagođavaju spoljašnjim uticajima, dok su mašine blaženo nesvesne sveta oko sebe. Upravo zato što posedujemo osobine koje mašine nemaju, za ljude će (još) uvek biti mesta. Ljudski um, po svemu sudeći, još uvek nije moguće zameniti gomilom brojeva, makar ih bilo 175 milijardi.
Da li je parna mašina obesmislila ljudski rad? Nije, baš kao što ni montažna traka nije eliminisala radnika u automobilskoj industriji. Možda je prestala potreba za nekvalifikovanom radnom snagom, ali su se zato pojavila kreativnija radna mesta: umesto spajanjem delova, ljudi se danas mnogo više bave dizajnom, konstrukcijom, optimizacijom, ekološkim aspektima i istraživanjem. I pored sve automatizacije, prosečni radnik u automobilskoj industriji danas zarađuje više nego pre par decenija. I od kompjutera se nekad očekivalo da u potpunosti zamene ljude koji su računali “peške” ili se bavili tabelama iscrtanim na ogromnim papirima. Ti ljudi nisu nestali, prekvalifikovali su se u stručnjake za Excel i programiranje. Rađaju se nova, bolje plaćena zanimanja, neka stara se gase, a gubitnici će biti jedino oni koji tu promenu odbijaju da prihvate.
dr Saša Marković
Kratka istorija ChatGPT-a i mašinskog učenja
Počeci mašinskog učenja sežu sve do ranih pedesetih godina prošlog veka kada su naučnici prvi put pokušavali da ljudsko razmišljanje i sposobnost prepoznavanja obrazaca pretoče u kompjuterske algoritme. Kao rezultat takvih pokušaja nastaju prve neuronske mreže koje vrlo brzo bivaju napuštene zbog nedovoljne razvijenosti tadašnjih računara, kao i male količine podataka potrebnih za treniranje neuronskih mreža.
Umesto toga, naučnici se okreću jednostavnijim modelima koji se umnogome baziraju isključivo na statistici. Takvo mašinsko učenje statističari su koristili još u prošlom veku, kako bi na osnovu nekih podataka iz prošlosti predvideli šta će se dešavati u budućnosti koristeći isključivo matematiku, ponekad čak i ručno izvodeći svoja izračunavanja.
Tek sa pojavom moćnih računara i razvojem interneta, naučnici su opet počeli da se bave neuronskim mrežama. Oblast mašinskog učenja koja izučava neuronske mreže i razvija modele bazirane na njima naziva se duboko učenje (eng. deep learning). Naziv u sebi odražava činjenicu da su neuronske mreže slojevite i da čak ni programeri koji su ih modelirali nisu sasvim sigurni šta se u unutrašnjim slojevima dešava.
Eksploziju veštačke inteligencije u današnje vreme ispratili su svi giganti IT industrije poput Facebook-a sa svojim softverom za prepoznavanje lica, Google-a sa svojim “Bardom” koji bi trebalo da predstavlja pandan ChatGPT-u i Microsoft-a sa “HoloLensom”, naočarama za virtuelnu realnost. Takođe, porast popularnosti dubokog učenja i veštačke inteligencije doveo je i do rađanja mnogih novih kompanija.
Kompaniju OpenAI, kao neprofitnu organizaciju, osnovala je 2015. godina grupa tehnoloških lidera među kojima su bili Elon Mask, Sem Altman, Greg Brokman i drugi. U periodu od 2015. do 2018. godine, OpenAI sarađuje s vodećim IT firmama kao i s prestižnim akademskim institucijama dajući aktivan doprinos svetskom istraživanju dubokog učenja. I pored toga, Elon Mask napušta kompaniju 2018. godine smatrajući da OpenAI nije ispunio očekivanja. Naredne godine OpenAI postaje profitna kompanija.
Sredinom 2018. godine OpenAI objavljuje GPT, svoj prvi veliki jezički model. GPT je imao značajan uticaj na razvoj različitih aplikacija koje se oslanjaju na prirodni jezik, uključujući prevođenje, odgovaranje na pitanja i automatizovano pisanje. U februaru 2019. godine OpenAI objavljuje novu verziju svog jezičkog modela, GPT-2, koji je bio znatno veći i sposobniji od prethodne verzije. GPT-2 je postao poznat zbog impresivnog kvaliteta generisanog teksta, što je kod mnogih izazvalo zabrinutost da bi takva tehnologija mogla biti zloupotrebljena za kreiranje lažnih vesti i drugih oblika dezinformacija. Možda zbog toga OpenAI nikad nije otkrio sve detalje GPT-2 modela. Već naredne godine, nastavljajući sa velikim dostignućima, OpenAI najavljuje novi model GPT-3 i ulazi u partnerstvo sa Majkrosoftom. Ovo je Majkrosoftu dalo mogućnost da, kao najveći investitor u OpenAI, može da koristi njegove modele za svoje potrebe. Godine 2021. OpenAI izbacuje i Dall-E, model koji generiše slike na osnovu opisa koji zadaje korisnik.
U naredne dve godine rad OpenAI-a na veštačkoj inteligenciji kulminira: u novembru 2022. godine kompanija izbacuje ChatGPT, program optimizovan za vođenje dijaloga zasnovan na jezičkom modelu GPT-3.5, kao i Dall-E2, najnaprednijeg “robota slikara” do sada (neke od njegovih ilustracija naći ćete u ovom tekstu). I tu nije kraj: u probni rad već je puštena nova verzija jezičkog modela, GPT-4, najveća i najsnažnija do sada, sa više od hiljadu milijardi konfigurabilnih parametara.
Vrednost kompanije na berzi danas se procenjuje na čitavih 20 milijardi dolara, pri čemu samo Majkrosoftova investicija iznosi milijardu dolara. Godišnji prihod kompanije tokom 2023. godine trebalo bi da dostigne 200 miliona dolara, sa tendencijom da on tokom naredne godine bude upetostručen. Odgovor konkurencije još uvek se čeka.
Luka Marković
Kako rade neuronske mreže
Zamislite da treba da napišete kompjuterski program koji će imati naizgled jednostavan zadatak – da na osnovu fotografije određene osobe prepozna da li je na njoj muška ili ženska osoba.
U programiranju je često korisno da, pre pisanja bilo kakvog koda, prvo razmislimo na koji način bi običan čovek izvršio zadatak koji bismo zadali računaru. Za čoveka je ovo rutinska stvar – mi smo, jednostavno, tokom života postepeno naučili da razlikujemo muška i ženska lica. Zašto ne bismo pokušali da, kroz program koji pišemo, omogućimo računaru da uči slično nama? To bi značilo da bismo programu prvo prosledili veliki broj portreta na osnovu kojih bi kompjuter postepeno naučio da raspoznaje razlike između muških i ženskih lica. Jednom “istreniran”, kompjuter bi kasnije mogao da klasifikuje portrete prema polu koristeći ono što je naučio.
Za ovako nešto potrebne su nam neuronske mreže. Modelovane po ugledu na ljudski mozak, neuronske mreže sastoje se od virtuelnih “neurona” koji su međusobno gusto povezani. Većina današnjih neuronskih mreža organizovana je u slojeve koji se sekvencijalno nižu. Prvi sloj mreže prihvata ulazne podatke, poslednji sloj generiše izlaz, a slojevi koji se nalaze između ostaju skriveni. Protok podataka kroz mrežu obično je jednosmeran, od ulaznog ka izlaznom sloju, ali se danas viđaju i mreže u kojima se podaci kreću na složenije načine. Svaka veza između dva neurona ima određenu konfigurabilnu “težinu” koja definiše u kojoj meri jedan neuron utiče na drugi.
Bitno je napomenuti da se na samom početku podaci moraju obraditi tako da ih neuronska mreža razume. Bilo da je u pitanju slika, zvuk ili tekst, neuronska mreža, kao i svaki kompjuterski program, ne razume ništa osim brojeva. Prilikom kretanja kroz mrežu podaci bivaju transformisani i svojim prolaskom kroz mrežu aktiviraju određene neurone koji dalje aktiviraju druge grupe neurona, sve dok mreža ne izbaci konačan rezultat (u našem slučaju to može da bude nula ako je u pitanju portret osobe muškog pola, ili jedan ako je u pitanju portret ženske osobe).
Pre početka rada, neuronske mreže su tabula rasa, nalik na tek rođeno dete, i svaki njihov konfigurabilni parametar podešen je na neki slučajan broj. Neuronska mreža uči tako što joj se serviraju pitanja za koja znamo tačno rešenje. U početku, neuronska mreža daje praktično nasumične odgovore. Međutim, poređenjem svojih nasumičnih odgovora sa tačnim odgovorima, uz obilno korišćenje matematike, neuronska mreža ume da popravi veze između svojih neurona, da samu sebe rekonfiguriše i tako se bolje pripremi za narednu fotografiju. Ovaj proces naziva se treniranje neuronske mreže i obavlja se u epohama. U svakoj epohi neuronska mreža “vežba” na novom setu fotografija i tačnih odgovora, postepeno popravljajući svoja predviđanja, sve dok na kraju ne ostvari zavidnu preciznost.
ChatGPT, iako značajno složeniji od prethodno opisane neuronske mreže, zapravo koristi isti princip. Kao i sve što se zasniva na neuronskim mrežama, ChatGPT-u su potrebni podaci na osnovu kojih će naučiti da obavlja sve što se od njega traži. Za ovu svrhu, kompanija OpenAI je odlučila da iskoristi praktično sve što je ikada napisano na internetu (45 terabajta teksta sa oko 500 milijardi reči). Da bi se iz ovolike količine podataka izvukao smisao, ChatGPT je konstruisan kao skup neuronskih mreža koje blisko sarađuju. Upravo zato je ChatGPT u mogućnosti da radi razne stvari, od prevoda teksta na više od 100 različitih jezika do parafraziranja i proširivanja teksta koji dobije od strane korisnika. Ovakav jedan monstrum od programa zahteva ogroman broj neurona i još veći broj veza između njih. Samim tim, ChatGPT ima ogroman broj parametara koji kontrolišu njegov rad.
Čitav proces učenja odvija se na robusnom hardveru, super-računaru sastavljenom od više stotina procesora s praktično neograničenom količinom memorije. Troškovi ovako angažovanih resursa veći su od tri miliona dolara mesečno. Ni proces učenja nije ništa jeftiniji: procenjuje se da jedan višemesečni trening ChatGPT-a košta više od deset miliona dolara. Za neuronsku mrežu koja obavlja naš prost zadatak raspoznavanja polova potrebno je malo više od 100 hiljada parametara, dok je za aktuelnu verziju ChatGPT-a taj broj oko 175 milijardi što je, složićete se, teško zamisliv broj.
Šta se zbiva u zemlji i svetu, šta ima u novinama i kako provesti vreme?
Svake srede u podne Međuvreme stiže elektronskom poštom. To je sasvim solidan njuzleter i zato se prijavite!
Zašto je svako ko se bavio upotrebom neutvrđenog tipa akustičnog oružja na studentskom protestu 15. marta postao neprijatelj države, terorista i atentator na Vučića? Zbog čega bi i Berija pozavidio Biji na ovoj operaciji? Kako režim u Beogradu 2026. nastoji stvoriti atmosferu nalik na onu iz Moskve 1937
Podaci Vrhovnog javnog tužilaštva pokazuju da poslednjih godina raste broj zahteva koje tužioci upućuju policiji radi prikupljanja potrebnih obaveštenja, ali da odgovori na te zahteve sve češće izostaju. Reč je o prvoj i jednoj od najvažnijih radnji u predistražnom postupku, bez koje tužilaštvo u mnogim slučajevima ne može da nastavi istragu
Zašto su se na meti režima, pored studenata, našli verbalni delinkventi – analitičari, stručnjaci i novinari? Kako je Više javno tužilaštvo u svom saopštenju donelo presudu da su studenti sami sebe streljali zvučnim topom? I kako je Vučić tvrdio da Srbija uopšte nema zvučne topove, a ispostavilo se da ih ima, kao što je odmah posle pada novosadske nadstrešnice tvrdio da “jedino ona nije renovirana”, pa se brzinom svetlosti na društvenim mrežama utvrdilo da to nije istina? Na koji je način aktivirana medijska bomba u režimskim medijima sa unapred spremljenim spiskovima ljudi koji su učestvovali u “zaveri” i koje treba utući? I da li je reč o pokušaju zabrane studentskog pokreta
Pošto tužilac u Srbiji ne može da optuži osobu koja se kolima zaleće u građane, gledaoci RTS-a mogu videti kako se pred kamerama obesmišljava ta pravna institucija
Srbija će sačuvati mir, lokalni funkcioneri moraju da razgovaraju sa narodom ili će biti smenjeni, ekonomija raste brzo, žele da nas sruše jer Srbija grabi napred, nema više straha od “blokadera”, predsednik je žrtva, biće veće plate i penzije. Na osnovu iskustva, po svoj prilici ovako će izgledati Vučićeve poruke na predstojećem mitingu
Manje je važno šta će pisati u službenim beleškama sa saslušanja Aleksandra Radića. Mnogo je važnije šta će večeras prolaziti kroz glave hiljada ljudi koji su o „zvučnom topu" govorili, pisali, svedočili ili tražili pomoć. Ako je odgovor: „Bože, samo da ne dođu i po mene", onda je cilj postignut
Arhiva nedeljnika Vreme obuhvata sva naša digitalna izdanja, još od samog početka našeg rada. Svi brojevi se mogu preuzeti u PDF format, kupovinom digitalnog izdanja, ili možete pročitati sve dostupne tekstove iz odabranog izdanja.
Napravimo li listu potreba televizije Pink, postaće nam jasno da su četbotovi savršeni voditelji, poput androida kojeg je nedavno predstavio Željko Mitrović kroz razgovor sa voditeljkom-robotom
Veštačka inteligencija između definicije slobode i slobode definicije
Oprez nikada nije naodmet. Eto, recimo, vozovi. Kada se u devetnaestom veku Srbiji ukazala realna šansa da zemljom krene voz, zapodela se rasprava o toj đavoljoj napravi, te uopšte potrebi za njom, rasprava koja bi se po dubini besmisla savršeno uklopila u današnju Srbiju. Ili, recimo, atomska energija (bez dragocenih priloga iz Srbije, doduše). Čovek je prvo napravio atomsku bombu, a onda je počeo da se češka po glavi (drugim rečima: da razmišlja o posledicama), ali je bilo kasno. Možda je Helderlin u pravu kada kaže da upravo u opasnosti leži ono što će nas spasiti, ali i u onome što nas može spasiti nalazi se klica naše propasti